Laboratoř zpracování řeči
![]() Katedra teorie obvodů, Technická 2, 160 00 Praha 6
Katedra teorie obvodů, Technická 2, 160 00 Praha 6
Tel: +420 224 352 049,
Fax: +420 233 339 805
http://noel.feld.cvut.cz/speechlab
Kdo jsme?
 doc. Ing. Petr Pollák, CSc.
doc. Ing. Petr Pollák, CSc.
Vedoucí skupiny - řešená problematika: rozpoznávání řeči s užším zaměřením na robustní techniky pro rozpoznávání v hlučném prostředí, rozpoznávání spontánní řeči, speciální parametrizace řeči, sběr řečových databází pro trénování rozpoznávacích systémů, zvýrazňování řeči v komunikačních aplikacích, algoritmy detekce řeči, fonetická segmentace, aplikace fonetické a lingvistické informace ve zpracování řeči.
Ing. Petr Mizera
Doktorand - řešená problematika: rozpoznávání řeči, aplikace neuronových sítí v systémech rozpoznávání řeči, fonetická segmentace, artikulační příznaky
Ing. Michal Borský
Doktorand - řešená problematika: rozpoznávání řeči s užším zaměřením na robustnost na úrovni akustického modelování (diskriminativní metody trénování, adaptační techniky), zpracování narušené řeči, zpracování komprimované řeči (MP3)
Studenti magisterských programů řešící své diplomové práce a podílející se na řešení interního grantu ČVUT Zdeněk Patč, Aleš Brich, Jiří Fiala, Jiří Valíček.
Jakým výzkumem se zabýváme
Obecně se zabýváme analýzou a zpracováním řečového signálu se zaměřením na systémy rozpoznávání řeči a zvýrazňování řeči pro komunikační účely. Naše aktuální aktivity směřují především k následujícím dílčím úlohám:
- rozpoznávání spojité řeči s velkým slovníkem s užším zaměřením na zpracování narušené řeči z hlučného prostředí nebo spontánních promluv
- extrakce příznaků se zaměřením na robustnost, zahrnutí informance o produkci řeči do příznakového vektoru (artikulční příznaky)
- optimalizace akustického modelování v systémech na bázi HMM (diskriminativní a adaptační techniky, kombinace ANN/HMM)
- jazykového modelování pro spontánní reč (slovníky s redukovanou výslovností, LM založené na třídách)
- automatická fonetická segmentace
- sběr a příprava řečových a textových dat
- detekce řečové aktivity
K čemu to je
Výše uvedené rozpoznávací úlohy nacházejí uplatnění v systémech pro on-line přepis řeči do textové podoby, typické příklady takových systémů představují diktovací aplikace v PC, on-line titulkování video pořadů, on-line či off-line transkripce audio záznamů s případnou indexací pro archivaci, hlasem řízenné telefonní informační systémy (nejjednodušší hlasové ovládání bývá používáno pro nahrazení nedostupné tónové volby, existují i systémy s komunikací přirozeným dialogem), systémy hlasového ovládání různých zařízení (velmi často v automobilu), systémy pro fonetickou segmentaci jako podpora základního fonetického výzkumu či speciálních technik analýzy řeči (např. patologické řeči). Zvýrazňování reči nachází uplatnění při jakékoliv komunikaci v hlučném prostředí, kdy odstranění šumu před přenosem výrazně zvyšuje srozumitelnost promluvy pro vzdáleného mluvčího, a také při extrakci příznaků pro rozpoznávání šumem narušené řeči (řeč z jedoucího automobilu, z veřejných prostranství, v místnostech s ozvěnou, řeč snímánou vzdáledným mikrofonem, atd.). Detektory řečové aktivity jsou nedílnou součástí řady systémů rozpoznávání či zvýrazňování řeči (detekce začátku a konce promluvy při rozpoznávání povelů, odhad charaktersitik pozadí při zvýrazňování, apod.). Sběr a následné zpracování řečových a textových dat je nezbytné pro trénování rozpoznávacích systémů, které jsou založené na statistických modelech či na principech umělé inteligence.
Na čem konkrétně pracujeme
Rozpoznávání spojité a spontánní řeči
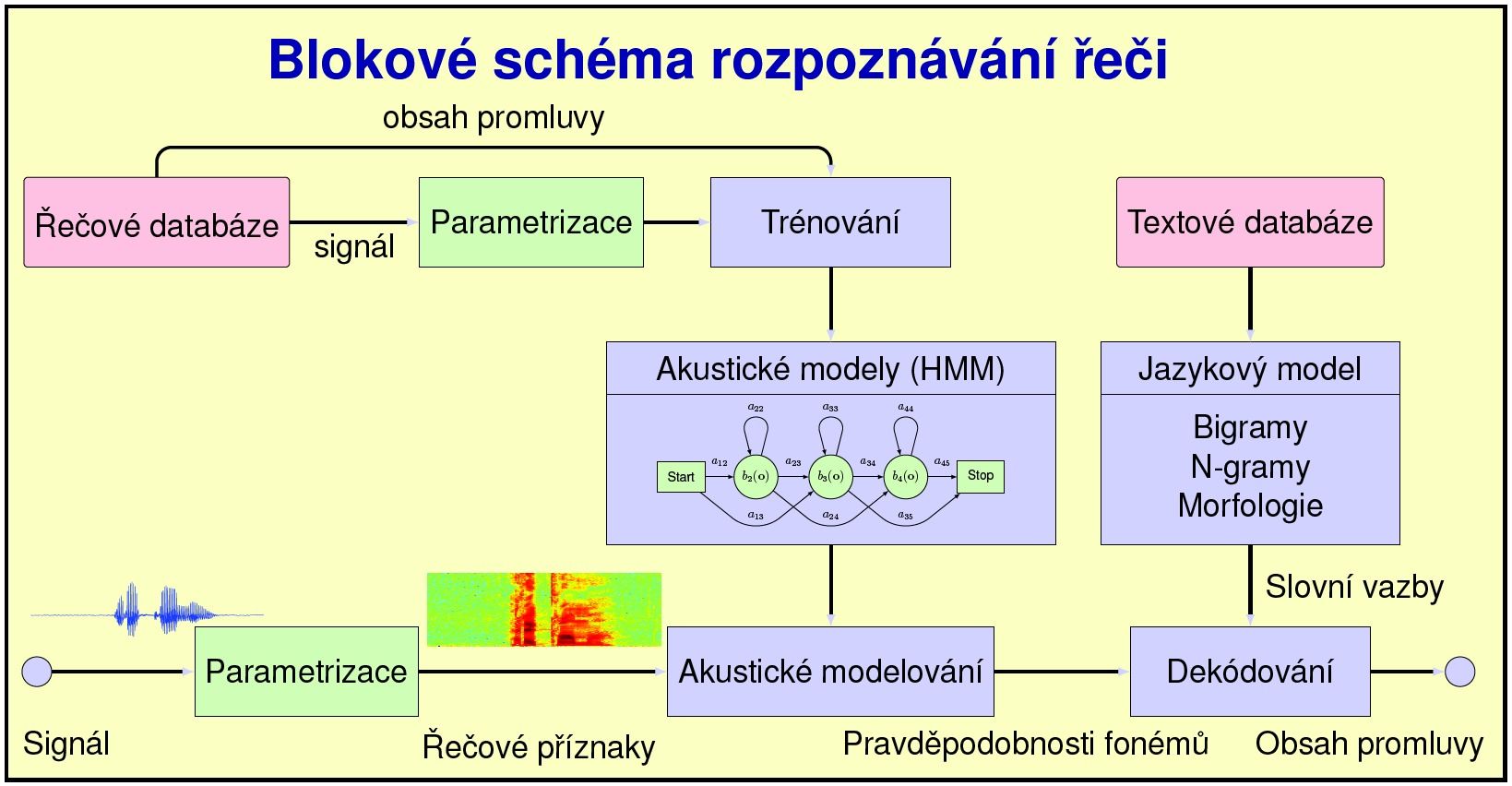
Hlavním cílem našich aktivit je optimalizace rozpoznávání spojité řeči s užším zaměřením na rozpoznávání spontánní a neformální řeči, kde nejdůležitější aktuálně řešené problémy jsou
- v první řadě návrh rozpoznávání spojité a spontánní řeči pro češtinu
- v rámci různých srovnávacích experimentů pracujeme i s vybranými systémy pro jiné jazyky (zejména angličtinu, slovenštinu, němčinu, francouzštinu)
- jazykového modelování, které poskytuje dekodéru informaci o možných mezislovních vazbách, používáme standardní n-gramové jazykové modely (obvykle bigramy, trigramy), které optimalizujeme pro spolehlivější rozpoznávání neformální řeči
- dekódování spojité řeči s využitím dostupných systémů a nástrojů na bázi konečných stavových automatů (FST), zejména KALDI nástrojů
Parametrizace řečového signálu
Parametrizace řečového signálu představuje výběr vhodných příznaků pro následnou klasifikaci v dalších stupních rozpoznávacího systému. V této oblasti podrobně studujeme
- vlastnosti základních technik (MFCC resp. PLP kepstrální koeficienty) v různých podmínkách s drobnými modifikacemi
- techniky pracujícím s delším kontextem v příznakovém vektoru (TRAP, RASTA, MULTI-RASTA)
- v rámci posledních aktivit i vlastnosti tzv. artikulačních příznaků
- ve výše uvedených speciálních technikách jsou využívány neuronové sítě resp. v poslední době stále více se uplatňující hluboké sítě s větším množstvím skrytých vrstev
Robustní rozpoznávání řeči

Spolehlivé rozpoznávání běžné řeči obsahující i různé typy rušení je důležitým předpokladem aplikace rozpoznávačů v běžných podmínkách. V našich aktivitách pro zvýšení této spolehlivosti se věnujeme řešení následujících problémů:
- studiu vlivu a možnosti potlačení aditivního rušení v průběhu parametrizace řeči
- významným produktem je nástroj CtuCopy, který implementuje různé metody parametrizace (zahrnující i potlačení šumu) a je kompatibilní s celosvětově používanými nástroji HTK a KALDI
- možnosti eliminace rušení na úrovni akustického modelování, zejména pak na bázi aplikací vhodně zvolené trénovací resp. adaptační techniky
- jsou také zkoumány vlastnosti speciálních architektur rozpoznávačů řeči jako ANN/HMM, DNN/HMM resp. TANDEM
Implementace a softwarové simulace rozpoznávání řeči

Nemalá část aktivit v oblasti rozpoznávání řeči je též věnována vlastním implementacím vývojových systémů rozpoznávání řeči. Aktivity v této oblasti představují především
- využití volně dostupných nástrojů, které jsou průběžně vyvíjené a pomocí kterých lze realizovat vývojové, testovací i finální verze rozpoznávačů (aktuálně zejména KALDI nástroje)
- práci na paralelním výpočetním klastru pod operačním systémem Linux, který zajišťuje požadovaný velký výkon pro náročné výpočty při trénování rozpoznávačů i dekódování rozpoznávané řeči a kde realizujeme většinu experimentů
- realizaci implementací hlasového ovládání v rámci jednoduchých aplikací na PC nebo v chytrých telefonech s OS Android
Fonetická segmentace promluvy
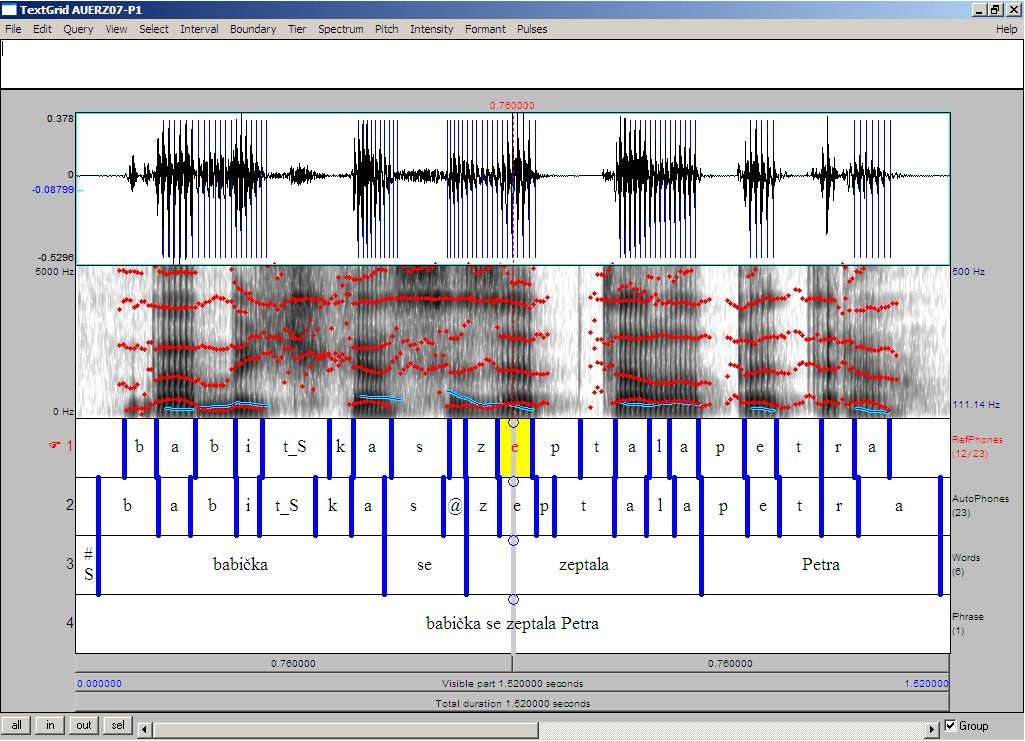
V této oblasti spolupracujeme s experty v oblasti fonetiky, lingvistiky resp. psycholingvistiky, kteří naše systémy využívají ve svém výzkumu resp. s nimi konzultujeme optimalizace rozpoznávacích systému využívajících informace o produkci řeči. Aktivity směřujeme k:
- realizace segmentace v rozsáhlých databází pro účely trénování neuronových sítí
- automatické presegmentace v nástrojích pro detailní fonetickou analýzu
- výzkumu variability výslovnosti zejména při zpracování spontánní a neformální řeči
- tvorbu nástroje pro iteraktivní segmentaci v uživatelském prostředí programu Praat, viz obrázek
Detekce řečové aktivity
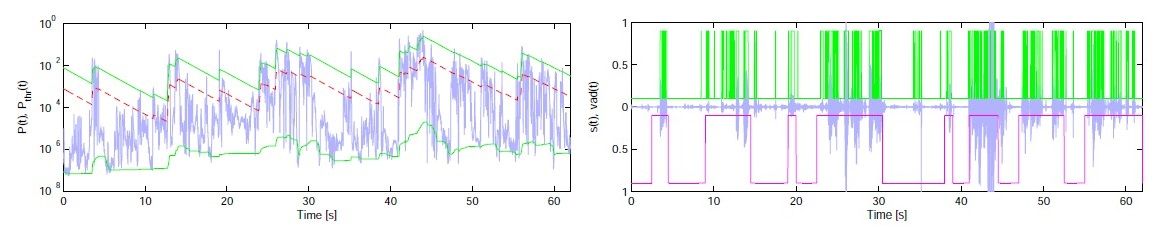
V této oblasti jsou studovány algorimty detekce řeči na bázi:
- energetických, kepstrálních či koherenčních charakteristik
- statistického modelování vybraných příznaků (GMM)
- umělých neuronových sítí
Sběr řečových a textových databází

Řečové databáze jsou nezbytné pro tvorbu systémů rozpoznávání řeči, nebo jsou zdrojem informace o variabilitě akustických charakteristik promluvy (řečové databáze) či o pravděpododbnosti konkrétního slovního kontextu (textové databáze). V této oblasti jsme se podíleli na vzniku několika rozsáhlých databázích v rámci evropských projektů či na bázi bilaterálních komerčních spoluprací, které nyní využíváme v našem výzkumu, tj.
- telefonní databáze ČÍSLOVKY a Czech SpeechDat, obě s cca 1000 mluvčími (dostupné přes http://www.elra.info
- česká verze databáze SPEECON, 650 dospělých mluvčích a 50 dětí v různých prostředích (viz http://www.elra.info)
- 1000 mluvčích v prostředí automobilu pro TEMIC SDS
- databáze s evokovaným Lombardovým jevem
- databáze přednášek z oblasti zpracování řečových a biologických signálů
- česká a slovenská verze LC-Star lexikonů (viz http://www.elra.info)
- databáze spontánní a neformální komunikace, Nijmegen Corpus of Causal Czech (viz http://www.mirjamernestus.nl/Ernestus/NCCCz/index.php)



Kdo financuje náš výzkum
Náš výzkum byl v minulých letech podporován granty GAČR (1996-2011), AV ČR (2004-2007), COST (1994-2005), výzkumným zaměrem (2005-2011), FRVŠ (2010, 2011), interní grant ČVUT (2012-2013). Podíleli jsme se na Evropských projektech SpeechDat-E (1999-2000), SPEECON (2002-2003), LC-StarII (2006-2007). V rámci bilaterálních projektů jsme spolupracovali s firmami Siemens AG, Muenchen, Germany (1999, 2006), Škoda Mladá Boleslav (2002-2003), TEMIC-Harman/Becker, Ulm, Germany (2000-2004), resp. Radboud University of Nijmegen, Netherlands (2008-2009).
Aktuálně je náš výzkum podporován interním grantem ČVUT SGS14/191/OHK3/3T/13 (2014-2016), další projekt je aktuálně v grantové soutěži GAČR.
V rámci hospodářské činnosti aktuálně řešíme dílčí projekty pro firmu ZOOM International.
S kým spolupracujeme
Úzce spolupracujeme s řadou odborníků z různých pracovišť, aktuálně zejména z následujících institucí:
- Radboud University of Nijmegen a Max Plank Institute for Psycholinguistics, Nijmegen
- ZOOM International
- Fonetický ústav FF UK - Praha
- Lingvistická sekce katedry anglistiky a amerikanistiky, FF Univerzita PAlackého, Olomouc
Neformálně příležitostně spolupracujeme také s univerzitními laboratořemi zpracování řeči, zejména s:
- FIT VUT - Brno --- Skupina zpracování řeči
- Technická univerzita v Liberci, Fakulta mechatroniky --- Laboratoř počítačového zpracování řeči
- Katedra kybernetiky Západočeské univerzity - Plzeň --- Oddělení umělé inteligence
Vybrané publikace
Výsledky naší práce jsme publikovali v mezinárodních impaktovaných vědeckých časopisech a na řadě prestižních mezinárodních kongresů a konferencí. Nejvýznamnější práce v minulém obodbí jsou:
- Mizera, P. - Pollák, P.: Robust Neural Network-Based Estimation of Articulatory Features For Czech. Neural Network World. 2014, vol. 24, no. 5, p. 463-478. ISSN 1210-0552.
- Procházka, V. - Pollák, P. - Žďánský, J. - Nouza, J.: Performance of Czech Speech Recognition with Language Models Created from Public Resources. Radioengineering. 2011, vol. 40, no. 4, p. 1002-1008. ISSN 1210-2512.
- Rajnoha, J. - Pollák, P.: ASR systems in Noisy Environment: Analysis and Solutions for Increasing Noise Robustness. Radioengineering. 2011, vol. 20, no. 1, p. 74-84. ISSN 1210-2512.
- Vondrášek, M. - Pollák, P.: Methods for Speech SNR Estimation: Evaluation Tool and Analysis of VAD Dependency. Radioengineering. 2005, vol. 14, no. 1, s. 6-11. ISSN 1210-2512.
- Ernestus, M. - Kockova-Amortova, L. - Pollák, P.: The Nijmegen Corpus of Casual Czech. In Proceedings of the 9th Language Resources and Evaluation Conference. Paris: ELRA - European Language Resources Association, 2014, vol. 1.
- Kolman, A. - Pollák, P.: Speech reduction in Czech. In LabPhone 14. The 14th Conference on Laboratory Phonology. Tokyo: National Institute for Japanese Linguistics in Tokyo, 2014.
- Mizera, P. - Pollák, P. - Kolman, A. - Ernestus, M.: Impact of Irregular Pronunciation on Phonetic Segmentation of Nijmegen Corpus of Casual Czech. In Text, Speech, and Dialogue. 17th International Conference, TSD 2014. Heidelberg: Springer, 2014, vol. 1, p. 499-507.
- Pollák, P. - Borský, M.: Small and Large Vocabulary Speech Recognition of MP3 Data under Real-Word Conditions: Experimental Study. Communications in Computer and Information Science. 2012, vol. 314, p. 409-419.
- Borský, M. - Pollák, P.: The optimization of PLP feature extraction for LVCSR recognition of MP3 data. In 19th International Conference on Applied Electronics 2014. Pilsen: University of West Bohemia, 2014, p. 55-58.
- Pollák, P. - Běhunek, M.: Accuracy of MP3 Speech Recognition Under Real-World Conditions. Experimental Study. In Proceedings of SIGMAP 2011 - International Conference on Signal Processing and Multimedia Applications. [CD-ROM]. Sevilla: University of Seville, 2011, vol. 1, p. 5-10.
- Pollák, P. - Rajnoha, J.: Multi-Channel Database of Spontaneous Czech with Synchronization of Channels Recorded by Independent Devices. In Proceedings of the Seventh conference on International Language Resources and Evaluation (LREC'10), La Valleta, Malta, 2010.
- Volín, J. - Pollák, P.: The Dynamic Dimension of the Global Speech-Rhythm Attributes. In Proceedings of Interspeech 2009 [CD-ROM]. Brighton, UK, 2009, p. 1543-1546.
- Pollák, P. - Rajnoha, J.: Long Recording Segmentation Based on Simple Power Voice Activity Detection with Adaptive Threshold and Post-Processing. In SPECOM 2009 Proceedings. St. Petersburg, Russia, 2009, p. 55-60.
- Pollák, P. - Volín, J. - Skarnitzl, R.: Phone Segmentation Tool with Integrated Pronunciation Lexicon and Czech Phonetically Labelled Reference Database. In 6th International Conference on Language Resources and Evaluation. Marrakech, Morocco, 2008, vol. 1, p. 1-5.
- Uhlíř, J. - Sovka, P. - Pollák, P. - Hanžl, V. - Čmejla, R.: Technologie hlasových komunikací. 1. vyd. Praha: Nakladatelství ČVUT, 2007. 276 s. ISBN 978-80-01-03888-8.
Nejvýznamnější pubplikace jsou přístupné on-line na stránkách Laboratoře zpracování řečového signálu, v sekci Publikace